
Ships—sexist or sexy?
_-_March_17,_1924.jpg)
Sexism is a hot topic on Wikipedia at the moment. The Countering systemic bias WikiProject uses Tom Simonite's "The Decline of Wikipedia" to highlight "... the effect of systemic bias and policy creep on recent downward trends in the number of editors available to support Wikipedia's range and coverage of topics." It cites the New York Times to say that "Wikipedia has been criticized by some journalists and academics for lacking not only women contributors but also extensive and in-depth encyclopedic attention to many topics regarding gender."
A Wikimedia Foundation study found that fewer than 13% of contributors to Wikipedia are women. Former WMF Executive Director Sue Gardner said increasing diversity was about making the encyclopaedia "as good as it could be." Possible factors cited as discouraging women included the "obsessive fact-loving realm" and the necessity to be "open to very difficult, high-conflict people, even misogynists." In August 2014, Wikipedia co-founder Jimmy Wales announced in a BBC interview the Wikimedia Foundation's plans for "doubling down" on gender bias at Wikipedia.
Grammatical gender has not been a feature of English since the 12th century. The use of the feminine pronoun "she" to refer to countries survived in some writing until the early 20th century, but is almost unknown nowadays. Wikipedia, as a modern encyclopedia, follows this trend: we do not talk about France or the United States as "she", except occasionally in quotations.
In Wikipedia's articles, the use of "she" to describe naval ships is near-universal, despite a successful and ongoing effort to improve the quality of these articles by the Military History and Ship WikiProjects. The consensus is that the first major editor of an article gets to decide for all time whether an article uses "she" or "it". It's obvious from the preponderance of "she" in the articles that almost all of them have been written by those with a preference for "she", which under our current rules is fine. This leaves naval articles as the last bastion of grammatical gender on Wikipedia.
As a man with a fascination for machines, including war machines, I've always had a particular horror of men who describe their cars, motorbikes, or aeroplanes as "she". Without getting too psychoanalytical, this seems to be evidence of ingrained and systematic sexism. The AP style guide and the Lloyd's Register discourage "she" for ships, and the Chicago Manual of Style has stated since 2003: "When a pronoun is used to refer to a vessel, the neuter it or its (rather than she or her) is preferred". Some of my older naval books still use "she", but the modern academic standard in all serious works is to omit it as an archaic usage.
_3_and_other_members_of_the_Navy_women%27s_dragon_boat_team_cheer_after_winning_first_place_over_the_Army,_Air_Force_and_Marines_during_the_a.jpg)
While these justifications are no doubt given tongue-in-cheek, in my value-system the casual sexism is obvious. Aesthetically this jars, and in terms of the embedded values of language, the use of a feminine pronoun to describe a killing machine crewed mainly by men jars too.
The place of women in Western society has undergone a huge change in the past 100 years. Women were allowed to vote in elections after much controversy in most countries after World War I, with Switzerland holding out until 1971. In the United States Navy, women have been recruited since 1917. In the 1940s, a special auxiliary service for women, WAVES, was set up. Women were expected to be non-combatants. By the 1970s, women were eligible for most surface combat roles and the first female naval aviators qualified. American submarines opened their hatches to women only in the last few years. In Britain, the Royal Navy first allowed women to go to sea in 1990 and it was 2014 before the first female submariners were admitted.
Perhaps as women penetrate this male preserve, this last remnant of grammatical gender could be allowed to wither from our project. Wikipedia generally has a proud tradition of being conservative in what we include in articles, but we claim to have a progressive attitude towards addressing systemic bias in how we write. Spinal Tap depicts a male rock star unable to understand criticism of the band's new album cover as being "sexist"; he asks "What's wrong with being sexy?" That was a 1984 satire on the problem of ingrained sexism; are male editors of ship-related articles in 2014 unconsciously perpetuating the same misogyny satirised in the film?
If Lila Tretikov and Jimmy Wales (not to mention the millions of volunteers who write our articles) are serious about helping us create a female-friendly editing environment, reforming the pronoun we use for naval ships might be an obvious place to start.
- The views expressed in this op-ed are those of the author only; responses and critical commentary are invited in the comments section. The Signpost welcomes proposals for op-eds at our opinion desk or through email.
Reader comments
College player falsely linked to sports scandal by Wikipedia; the Nobel Prizes
Wikipedia article falsely links player to college sports scandal for six years

Ben Koo of the sports blog Awful Announcing investigated (October 9) how player Joe Streater's name became involved in recent years with a historic sports scandal, the 1978–79 Boston College basketball point shaving scandal. The scandal involved Boston College basketball players conspiring with mobsters, including Henry Hill, who was immortalized by the film Goodfellas, to deliberately reduce the point spread so they could profit through illegal sports gambling.
Streater was a basketball player at Boston College, a private university in Boston, Massachusetts. One former Boston College player recalled that "He had mad skills and smarts." However, he was not even on the team at the time of the scandal, having left the team and college the previous season after playing only eleven games, less than half of the scheduled games for the 1977-78 season. Why Streater left, what he did following his time at Boston College, or even whether or not he is still alive are all unknown, and Koo was unable to locate Streater.
Despite the frequency with which he is associated with the scandal, Streater is not mentioned in any of the important accounts of the incident, including the famous 1981 Sports Illustrated article describing Hill's first-person account, Associated Press reporter David Porter's 2002 book, Fixed: How Goodfellas Bought Boston College Basketball, or ESPN's 2014 documentary Playing for the Mob. Porter told Koo that he did not know of any involvement in the scandal by Streater or why his name has been repeatedly mentioned. He said "I have seen the name over the years and am mystified as well."
Koo found many mentions of Streater's name in connection with the scandal outside of these in-depth reports, including some from media outlets like the Associated Press, ESPN, and Sports Illustrated, which had reported on the scandal without mentioning Streater, most prominently a widely circulated 2012 Associated Press story. Koo could not find a story mentioning Streater in conjunction with the scandal dating before 2008. Koo concluded that the connection resulted from writers and journalists consulting Wikipedia or other sources which had repeated inaccurate information from Wikipedia.
Koo traced the addition of Streater's name to the Wikipedia article on the scandal to an August 12, 2008 edit by User:155.212.229.132, a Massachusetts-based IP address belonging to Goodwill Industries. The edit added Streater's name to the article five times and changed the amount of a payment from Hill from $500 to $2000. In December 2008, edits from the same IP address deleted a large amount material from the article on the scandal, including all of the references, as well as material from the article for NBA coach David Blatt, who Koo noted played against Streater when they were both high school basketball players in the Boston area. (The only other edits from the IP address were two November 2009 typographical corrections to the article Morgan Memorial Goodwill Industries, which is now a redirect to Goodwill Industries.)
The day before Koo's story was published, four of the mentions of Streater were removed from the Wikipedia article about the scandal by an IP address originating outside of Massachusetts. The remaining mention of his name was removed the next day by a different editor. Streater's name had been in the article for six years.
Wikipedia and the Nobel Prize

Each year, the week of announcements from the Swedish Academy regarding the new Nobel Prize laureates leaves many people, including professional journalists and commentators, scrambling to learn about winners who are often obscure outside their own fields, and Wikipedia is one of their first stops for information.
Slate reports (October 9) on a warning left for journalists in the article for the newest literature laureate, Patrick Modiano, by a Wikipedia editor adding a major update following the announcement. Lest a journalist who needed to make a quick blog post crib unverified details from the article, under the section heading "To The Reporter Now Copying from Wikipedia", the editor wrote "Be careful boy. Primary sources are still best for journos." The warning was removed from the article eleven minutes later.
Huffington Post UK complained (October 13) that the article for new economics laureate Jean Tirole contained little information about his work and was mostly a list of his lectures. It noted that an IP editor added the remark "YO, SOMEONE EDIT THIS STUFF IT LOOKS LIKE KRAP", though it was removed by another editor three minutes later.
IBN Live compares (October 13) Wikipedia traffic statistics for this year's two Nobel Peace Prize winners, Kailash Satyarthi and Malala Yousafzai. Pageviews for Satyarthi spiked on the day of the announcement, suggesting that readers wanted to learn more about the lesser known of the two, while pageviews for Yousafzai surpassed those for Satyarthi for the next two days.
In brief
- Wikipedia history unearthed: Gawker reports (October 16) on the new Tumblr blog started by John Overholt, Curator of Early Modern Books and Manuscripts at Harvard University's Houghton Library. The blog, First Drafts of History, posts screenshots from the early years of Wikipedia of the very first edits to now key articles, like Barack Obama, iPhone, and cheese. Overholt is no stranger to Wikipedia, as he works with Houghton's Wikipedian in residence, User:Rob at Houghton.
- The missing puzzle pieces: In Dawn, Wikipedia editor Saqib Qayyum Choudhry urges (October 15) Pakistanis to contribute to Wikipedia and fill in gaps in coverage about their country.
- Take it easy: When The News asked (October 14) the English post-punk band Eagulls about the hatnote on their Wikipedia article which reads "Not to be confused with the American band The Eagles," vocalist George Mitchell replied "I think I might have to go on there and change it. Last time I read it, it made me feel pretty sick."
- Wikimedia Ghana: GhanaWeb reports (October 14) on the Wikimedia Foundation's official recognition of the Wikimedia Ghana User Group as a Wikimedia user group.
- Radio Free Tajikistan: Radio Free Europe/Radio Liberty reports that Wikipedia is available again in Tajikistan as of October 13. Wikipedia and many news and social media websites, as well as SMS services, were blocked by the Tajik government on October 5 in anticipation of mass protests called for by opposition movement Group 24, protests which never occurred. Such blockages are a frequent occurrence in Tajikistan, which is nominally a democratic republic but has been ruled by President Emomali Rahmon since 1992.
- Your best friend: In the Chronicle of Higher Education, Dariusz Jemielniak (User:Pundit), author of Common Knowledge: An Ethnography of Wikipedia (see the Signpost book review), discusses why Wikipedia is "a Professor's Best Friend" (October 13).
- For just 20 cents a day: In Wired, Emily Dreyfuss explains (October 10) "Why I'm Giving Wikipedia 6 Bucks a Month".
Reader comments
One case closed and two opened
Banning Policy was closed on 12 October. Arbcom affirmed that users have "considerable leeway" in terms of how their talk pages are managed. Users Tarc (talk · contribs), Smallbones (talk · contribs), and Hell in a Bucket (talk · contribs) were all warned to refrain from edit warring and making inflammatory comments. Tarc was also topic banned from editing any of the administrator's noticeboards or User talk:Jimbo Wales, and from reinstating any edits that were reverted because they were made by a banned user.
New cases
Two new cases have been opened since the last arbitration report. Gender Gap Task Force was opened on 2 October and is in its evidence phase until 17 October. Landmark Worldwide was opened on 16 October and is also currently in the evidence phase.
In brief
- A request for comment has been opened by Beeblebrox (talk · contribs) on the topic of reforming the Ban Appeals Subcommittee.
- There are current open requests for arbitration on the topics of the historicity of Jesus, gamergate, and global warming.
Reader comments
Bells ring out at the Temple of the Dragon at Peace
-
 Bonshō bells, found in Buddhist temples in Japan, are the subject of a new featured article. This bell is from Ryōan-ji, The Temple of the Dragon at Peace, in Kyoto City.
Bonshō bells, found in Buddhist temples in Japan, are the subject of a new featured article. This bell is from Ryōan-ji, The Temple of the Dragon at Peace, in Kyoto City. -
 A new featured picture, showing a performance of Odissi, one of the eight classical dance forms of India.
A new featured picture, showing a performance of Odissi, one of the eight classical dance forms of India. -
 United States Secretary of State William H. Seward was noted for his opposition to slavery and his involvement with the Alaska Purchase, and is now the subject of a featured article.
United States Secretary of State William H. Seward was noted for his opposition to slavery and his involvement with the Alaska Purchase, and is now the subject of a featured article.




Featured articles
Nine featured articles were promoted this week.

- Caesar Hull (nominated by Cliftonian), a Southern Rhodesian-born flying ace in the Royal Air Force during the Second World War.
- Future Science Fiction and Science Fiction Stories (nominated by Mike Christie), were two American science fiction magazines that were titles under various names between 1939 and 1943 and again from 1950 to 1960.
- Briarcliff Manor, New York (nominated by ɱ), the main article in ɱ's drive to get all 17 Briarcliff Manor related articles to featured article/list status. This article on a suburban village in Westchester County, New York is the first article of the set to reach featured status.
- Fez (video game) (nominated by Czar), a 2012 indie puzzle platform game developed by Polytron Corporation and published by Polytron, Trapdoor, and Microsoft Studios.
- ...And Justice for All (album) (nominated by Retrohead), a album by Metallica released in 1988. As the nominator Retrohead said, "[The album is] a masterwork of technical thrash and musically, one of their finest hours."
- William H. Seward (nominated by Wehwalt), a US Secretary of State, who also served as Governor of New York and United States Senator, and lived from 1801 to 1872. He was a determined opponent of the spread of slavery in the years leading up to the American Civil War and a dominant figure in the Republican Party in its formative years. He was a leading contender for the party's presidential nomination in 1860, although Abraham Lincoln won the nomination and the election that year.
- Bonshō (nominated by Yunshui), are large bells found in Buddhist temples throughout Japan, used to summon monks to prayer and to demarcate periods of time. Rather than containing a clapper, the bells are struck from the outside, using either a hand-held mallet or a beam suspended on ropes. They are typically augmented and ornamented with a variety of bosses, raised bands and inscriptions. The earliest of these bells in Japan date to around 600 CE, although the general design is of much earlier Chinese origin and shares some of the features seen in ancient Chinese bells.
- 1850 Atlantic hurricane season (nominated by Juliancolton), one of many storm-related articles Juliancolton has helped reach featured status; his work on the topic dates back at least to 2008. This article details three significant tropical cyclones which struck areas on the US East Coast, some causing significant damage with high tides, strong winds, and torrential rainfall.
- Keswick, Cumbria (nominated by Tim riley and Dr. Blofeld) Keswick is a small town, known as the capital of the English Lake District. Its history goes back more than 700 years, and its literary associations are remarkable, from the Lake Poets to Hugh Walpole.


Featured pictures
Twenty-six featured pictures were promoted this week.
.jpg)



- Construction of the Monroe Street Bridge (created by W. O. Reed, restored by Lise Broer (Durova), and nominated by G755648) Weird seeing Durova's name crop up in this again. Anyway! The Monroe Street Bridge in Spokane, Washington was built in 1911, and at the time of construction was the largest concrete arch bridge in the United States.
- Odissi performer (created and nominated by Augustus Binu) Odissi is one of the eight classical dance forms of India, and has been reconstructed after having been repressed during the British Raj period. It is marked from other Indian dances through a "three part break": the head, chest and pelvis move independently from each other, as well as various stylized poses and stances.
- Dendrogramma enigmatica (created by Jean Just, Reinhardt Møbjerg Kristensen and Jørgen Olesen; nominated by Geni) Dendrogramma enigmatica are marine organisms that are roughly mushroom-shaped. The type specimen of Dendrogramma is one of two species in the genus Dendrogramma found in the ocean near Tasmania in 1986. The bizarre organisms may represent a new phylum of animals; such a discovery is an extremely rare event, to say the least. No new specimens have been found since the first expedition, and the formaldehyde-preserved organisms from that expedition are currently the only known examples of the two species, or any other in their genus or family.
- Dome of the Fatima Masumeh Shrine (created and nominated by Muhammad Mahdi Karim) The shrine of Fatima Masumeh is located in Qom which is considered by Shia Muslims to be the second most sacred city in Iran after Mashhad. Fatima Masumeh was the sister of the eighth Imam, 'Ali al-Rida, and the daughter of the seventh Imam, Musa al-Kadhim. Among the Shias, she is honored as a saint, and her shrine in Qom is considered one of the most significant shrines in Iran. The dome shown in the picture lies immediately above her burial chamber which also includes her three nieces.
- L'Hôtel national des Invalides, Paris (created by DXR, nominated by Tomer T) L'Hôtel national des Invalides (informally, Les Invalides), is a collection of buildings and monuments, all related to the military, including military museums, a military hospital and a retirement home for war veterans, located in the 7th arrondissement of Paris.
- The Gleaners (created by Jean-François Millet, nominated by Crisco 1492) One of Jean-François Millet's best-known paintings, it scandalized Parisian society of 1857 by sympathetically portraying the working classes, an uncomfortable reminder of both the French Revolution, and that Parisian society was built on the back of the poor labourers. While shocking at the time, it inspired generations of later artists, and, after the artist's death, grew rapidly in popularity.
- The Balcony (created by Edouard Manet, nominated by Hafspajen) An important and well-known painting, made in 1868 by Édouard Manet, The Balcony (Le balcon) was one of the key works marked the beginning of the impressionism, alongside Manet's other painting The Luncheon on the Grass (Le Déjeuner sur l’herbe, 1863). It is considered innovative and iconic and it went against the conventions of the time.
- Carnation, Lily, Lily, Rose (created by John Singer Sargent, nominated by SagaciousPhil) John Singer Sergeant's painting Carnation, Lily, Lily, Rose (named after a line in a song), shows his friend Fred Barnard's children Dolly and Polly lighting lanterns in the early evening. The carnations, lilies and roses are spreading their scent in the magically illuminated garden in the last rosy rays of the sun. Is it for a garden party? Or just for the fun of lightning up the night garden?
- Girl at Sewing Machine (created by Edward Hopper, nominated by Armbrust) Edward Hopper's 1921 painting, Girl at Sewing Machine, portrays a young girl sitting at a sewing machine in New York City, facing a window on a beautiful sunny day, believed to be a commentary by Hopper on solitude... It is currently housed in the Museo Thyssen-Bornemisza in Madrid, Spain.
- The Fog Warning (created by Winslow Homer, nominated by Hafspajen) Winslow Homer (1836 – 1910) was an original and interesting American painter, best known for his paintings with marine subjects. The Fog Warning illustrates a dramatic moment when the fisherman is fighting to get back to the boat before caught in the fog. He has grabbed the oars and he is on his way towards the ship, to escape from being fogbound. A dangerous situation: a boat lost out in the ocean was doomed.
- The Submission of Prince Dipo Negoro to General De Kock (created by Nicolaas Pieneman, nominated by Crisco 1492) Commissioned by General de Kock himself, The Submission of Prince Dipo Negoro to General De Kock depicts the Javanese leader Diponegoro surrendering at the end of the Java War, but leaves out a few aspects, like him being arrested after being promised safe passage.
- Japanese Invasion currency from the Philippines: One , five, ten, and fifty Philippine centavos from the 1942 series; one, five, and ten Philippine pesos from the 1942 series; one, five, and ten Philippine pesos from the 1943 series; one-hundred and five-hundred Philippine pesos from the 1944 series; and one-thousand Philippine pesos from the 1945 series (created by Empire of Japan, prepared by Godot13 from the National Numismatic Collection of the Smithsonian Institution; also nominated by Godot13) During the Japanese occupation of the Philippines, the Japanese issued their own printings of the Philippine peso. This money rapidly devalued - hence the ever-larger denominations as the printing run continued - and became known as "Mickey Mouse pesos", with whole bundles of them becoming necessary to buy anything by the end of the war.
- Fez gameplay (created by Polytron Corporation, nominated by czar, who also arranged for its release) We have, of course, already described Fez up in featured articles, but, as pointed out on the nomination page, this illustrates the rotation gameplay element of Fez that would be otherwise exceptionally difficult to describe - but is much easier with the video. Basically, the 3D world is reinterpreted as a 2D-platformer based on the position of the platforms as seen from the current viewpoint.
- Bothriechis schlegelii (created by Geoff Gallice, nominated by Tomer T) Found from southern Mexico to northern South America, the Bothriechis schlegelii has scales over its eyes, whose appearance gives it its common name of the "eyelash viper". It comes in a wide variety of colours, including red, yellow, brown, green, and pink - Catch them all! ...but, er, be careful, they are venomous.
-
 Dome of the Fatima Masumeh Shrine in Qom
Dome of the Fatima Masumeh Shrine in Qom -



Reader comments
<big>Attempting<ref>{{citation needed</ref>}} to parse <code>wikitext</code></big>
This week we sat down with The Earwig to learn about his wikitext parser, mwparserfromhell.
What is mwparserfromhell, and how did it get its name?
- mwparserfromhell (which I will abbreviate as mwpfh) is a Python parser for wikicode. In short, it allows bot developers (like those using pywikibot) to systematically analyze and manipulate wikitext, even in cases where it is complex or ambiguous.
- For example, let's say we want to see if a page transcludes a particular template, check whether it has a particular parameter, and if not, add it. A classic application would be a bot that dates {{citation needed}} tags. This isn't as simple as it sounds! A naive solution might use regexes, but then we need to check whether the parameter exists between the template's opening and closing brackets, but not get confused if it's inside of a template contained within the template (for example, if you had
{{citation needed|reason=This fact is important.{{citation needed|date=October 2014}}}}), whether the template is between <nowiki> tags, and so on... - mwparserfromhell makes this easy by creating a tree representation of the wikicode (loosely described as a parse tree) that can be converted back to wikicode after any modifications are made. It focuses on being as accurate as possible, both in terms of the tree representation being accurate, and the outputted wikicode being as similar to the original as possible.
- Its name comes courtesy of Σ, reflecting the somewhat insane nature of the project, and as an excuse for its frightening codebase.
What led you to develop it in the first place?
- I’ve been writing bots and tools/scripts for many years – situations like the one above come up a lot. Sure, ad hoc solutions using regexes work sometimes, but I wanted something that would work in more general cases. mwparserfromhell seemed like a project that would be useful to most bot developers, and of which there was no existing equivalent.
What were some of the challenges you faced or things that didn't go according to plan while developing the parser? How did you manage them?
- Oh, boy. It turns out that wikicode is a horrible, horrible language, for people and computers alike. It lacks a clear definition of how certain edge cases should be handled, and since mwparserfromhell’s goal is to be accurate, a lot of time was spent just trying to figure out how MediaWiki works. Many language parsers are designed to give up once they see a syntax error, like a missing bracket somewhere, but MediaWiki considers all possible wikitext to be valid, so a lot of mwpfh’s code involves making sense of some very questionable things (like templates nested inside of HTML tag attributes nested inside of external links, or the difference between
{{{{{foo}}bar}}}and{{{{{foo}}}bar}}) and handling them as closely as possible to the way MediaWiki does. Sometimes this is hard, but other times it is outright impossible and we have to make guesses. For example, if we imagine that the template{{close ref}}transcludes</ref>and the parser encounters the wikicode<ref>{{cite web|…}}{{close ref}}, it will appear as if the<ref>tag does not end, even though it does. This is a limitation inherent in the nature of parsing wikicode: we have no knowledge of the contents of the template, so we can't figure out every situation. mwparserfromhell compromises as best as it can, by treating the<ref>tag as ordinary text and fully parsing the two templates.
How does mwparserfromhell compare to other re-implementations of the MediaWiki parser, like Parsoid?
- Most projects like Parsoid (or MediaWiki’s own PHP parser) are designed to convert wikicode to HTML so that it can be viewed or edited by users. mwparserfromhell converts wikicode into a tree structure for bots, and that structure must contain enough information (such as HTML comments, whitespace, and malformed syntax that other parsers would outright ignore or try to correct) for it to be manipulated and converted back to wikitext with no unintentional modifications. Furthermore, it has less awareness of context than other parsers: because it is designed to deal with wikicode on a fairly abstract level, it doesn't know the contents of a template and can't make any substitutions. As noted above, this causes problems sometimes, but it's necessary for the parser to be useful to bots that are manipulating the templates themselves.
What is the most significant challenge that mwparserfromhell currently faces, and why?
- It’s a difficult, exhausting project that would ideally have multiple people working on it. Development has stalled recently as I've been busy with college, and additional eyes would be useful to point out potential issues or help out with open problems.
What's next for mwparserfromhell? Do you have any other cool projects you'd like to tell us about?
- Some wikitext constructs (primarily tables, but also parser functions and
#REDIRECTs) aren’t understood by mwparserfromhell, so I would like to implement those. There’s actually an open request to review some code for table support that I've been procrastinating on for a couple months now. Other than that, I have some plants to make it more efficient; mwpfh has some speed issues with ambiguous syntax on large pages. - My copyvio detection tool on Wikimedia Labs (which uses mwparserfromhell, by the way!) has seen a lot of improvements lately, including more accurate detection, more detailed search results, and a fresh new API. If you don't know about it or have only used it in the past, I invite you to give it a spin.
Reader comments
Now introducing ... mobile data
As reported in the Signpost last month, mobile views have not been historically included in the raw page count data provided by the Wikimedia Foundation. That has caused stats.grok.se as well as the WP:5000 report on which this report and the WP:TOP25 are based to lack that data. And this has led to a significant under count in total page views, as mobile views now account for about 30% of Wikipedia traffic. However, we are pleased to report that the WP:5000 has now been updated to include mobile views, including a column reflecting the percentage of views coming from mobile devices. This week's report is the first using the additional data.
We've noticed two primary effects from the inclusion of mobile view data so far. First, and most obviously, view counts are up. This week's #1, Ebola virus disease, had almost 4.3 million views, the best showing of a #1 article by far since the incredible 9.1 million which Robin Williams received after his death in August. To simply make the Top 25 this week, it took 484,791 views -- a big jump from only 240,000 views last week.
Second, we can also see that the percentage of mobile views an article receives varies by the type of article it is, as well as the source of its popularity. This week's #3, Moose, became popular due to a Reddit thread but only had 26% mobile views. Perhaps that general percentage will prove to hold true over time for Reddit popularity -- #6 this week, Age disparity in sexual relationships, was also made popular by a Reddit thread and had 26.5% mobile views.
Meanwhile, this week's #1 (Ebola virus disease) had 54.4% mobile views and #2 Ebola virus hit 64%. Contrast those numbers to this week's #10, Thor Heyerdahl, made popular by a Google Doodle. Only 15.7% of those views were from mobile sources. And Deaths in 2014, an article which often makes the Top 10, was reduced to #23 this week with only 19.9% mobile views. One might suppose that the very lengthy list-like (and sobering) nature of that article may make it less popular to read on the go. We'll continue to review how the inclusion of mobile data affects trends in article popularity, feel free to add your hypotheses to the comments.
For the full top 25 list, see WP:TOP25. See this section for an explanation of any exclusions.
For the week of 5-11 October, 2014, the ten most popular articles on Wikipedia, as determined from the report of the 5,000 most viewed pages, were:
Rank Article Class Views Image Notes 1 Ebola virus disease 
4,298,499 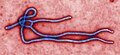
The death of Thomas Eric Duncan on October 8, the first person to die in the United States from Ebola virus disease, has only continued to increase attention to this subject, which is #1 for the second week in a row. 2 Ebola virus 
998,891 See #1. 3 Moose
966,086 
This week Reddit learned that "the Killer Whale is a natural predator of the Moose." The sentence which piqued their curiosity remarked that killer whales "are the moose's only known marine predator as they have been known to prey on them when swimming between islands out of North America's Northwest Coast." 4 American Horror Story: Freak Show
956,565 
The fourth season of the American Horror Story series debuted on 8 October 2014. Series co-creator Ryan Murphy (pictured at left) directed the first episode of the season. 5 Gone Girl (film) 
953,715 
This 2014 American mystery film starring Ben Affleck and Rosamund Pike (both pictured at left) was released in the United States on October 3. 6 Age disparity in sexual relationships
864,448 
This article owes it popularity to a Reddit thread. That this subject might be a topic of interest is not surprising to anyone who peruses the incredibly long List of films featuring romances of significant age disparity listed in the "see also" section. 7 Annabelle (film)
853,990 
This 2014 American horror film was released on October 3, and stars Annabelle Wallis, Ward Horton, and Alfre Woodard (pictured at left). 8 Ebola virus epidemic in West Africa
826,103 See #1 and #2. 9 Facebook
798,797 
A perennially popular article. 10 Thor Heyerdahl
779,723 
A Google Doodle honored what would have been 100th birthday of this Norwegian adventurer known for his 1947 Kon-Tiki expedition.



.jpg)


.JPG)

.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg&action=edit&redlink=1){kind=link}
{kind=link}
-1_Centavo_(1942).jpg){kind=link}
-5_Centavos_(1942).jpg){kind=link}
-10_Centavos_(1942).jpg){kind=link}
-50_Centavos_(1942).jpg){kind=link}
-1_Peso_(1942).jpg){kind=link}
-5_Pesos_(1942).jpg){kind=link}
-10_Pesos_(1942).jpg){kind=link}
-1_Peso_(1943).jpg){kind=link}
-5_Pesos_(1943).jpg){kind=link}
-10_Pesos_(1943).jpg){kind=link}
-100_Pesos_(1944).jpg){kind=link}
-500_Pesos_(1944).jpg){kind=link}
-1000_Pesos_(1945).jpg){kind=link}
{kind=link}
Reader comments
Signpost reaches the Midwest

Today, it's the turn of WikiProject Ohio to give us an interview probing deep into of how they manage to run a project covering one fiftieth of the United States, and the workings of how they manufacture their successes and other articles. They have gathered a staggering 66 pieces of Featured content, and 164 Good articles. 83 members might sound like a lot of Wikipedians to work on the topics of Ohio, but we selected just three to give us a flavor of what goes on behind their scenes. Our interviewees this week are Vjmlhds, Frank12 and Wikipelli.

What motivated you to join WikiProject Ohio? Do you live or have you ever lived in the state?
- Vjmlhds: As a life long Ohioan, I wanted to make sure that I did all I could to make Ohio related articles the best they could be.
- Frank12: I've only lived in Ohio and I was willing to team up with other Ohioans and those with interest in Ohio-related articles to provide useful and accurate content.
- Wikipelli: My family's history is rooted in Ohio. I have a great interest in the history of Ohio – specifically, the Columbiana County area.
Do you contribute to the projects of any other US states? How would you compare activity at WikiProject Ohio to activity at other state projects?
- Vjmlhds: No, and I can't really answer the second part, since I'm more focused on this project.
- Frank12: I have, many of them in other Midwestern states due to my fascination with the region. I can't really say either, but I get the impression that Ohio has a great deal of pride among its residents that are willing to showcase the great qualities of the state.
- Wikipelli: I have also been active in Virginia history projects.
Have you contributed to any of the project's 39 featured articles, 17 featured lists, 2 A-class articles, and 164 good articles? Are you currently working on promoting an article to FA or GA status?
- Vjmlhds: I've done my fair share of work on a couple of articles that meet those standards – The Miz (GA) and Cleveland (FA). And I've tried to get a few others up to that level, but to no avail...but I'm still working on it.
- Frank12: Yes, but nothing of great addition. If anything I try to add interesting tidbits, but I'm sure I'll contribute a lot if it's of a strong personal interest to me, which I've done here and there with other articles.
In addition to cities, counties, and geographic features, what are some interesting articles covered by the project?
- Vjmlhds: I like articles about the pro sports teams (especially the ones in Cleveland), as well as Ohio State Buckeyes football, plus I've done work on articles about pro wrestlers from the state (including The Miz as mentioned above).
- Frank12: I find the geographical articles very interesting as well as sports and college/university articles.
- Wikipelli: I like the articles relating to the NRHPs.
WikiProject Ohio has a large number of child projects, including ones for Cincinnati, Cleveland, Youngstown, Ohio State Highways, the Cincinnati Reds, Cleveland Browns, Columbus Blue Jackets, Cleveland Cavaliers, and Ohio Wesleyan University. Do you consider this a large project that needs to split off its major cities, or are those projects not doing so well as the statewide project?
- Vjmlhds: I think things are going along OK as is.
- Frank12: For now I think they can stay under the Ohio scope, but I wouldn't be surprised if one day the 3 Cs could go off on their own.
What are WikiProject Ohio's most urgent needs? How can a new member help today?
- Vjmlhds: The biggest thing any current or future member can do is just keep a look-out to make sure things stay up to standard.
- Frank12: Go after the articles that interest you most or you feel you can contribute to the best, and have fun with it!
Anything else you'd like to add?
- Vjmlhds: O-H....I-O!
- Frank12: I'll second that!
Next week, we'll take you on a trip to the orphanage. In the meanwhile, check out some other lost gems in the archive.
Reader comments