
Media viewer case is suspended
On 1 September, the Arbitrators voted to suspend the Media Viewer case for 60 days. After the suspension period is up, the case is to be closed unless the committee votes otherwise. The case suspension comes in response to several new initiatives and policies announced by the Wikimedia Foundation that may make the case moot. In the same motion, the committee declared that Eloquence's resignation of the administrator right was "under a cloud" and that he can only regain the right through another RfA.
Audit Subcommittee appointments
The Arbitrators voted to appoint Callanecc (talk · contribs), Joe Decker (talk · contribs) and MBisanz (talk · contribs), with DeltaQuad (talk · contribs) as the alternate, to the 2014 Audit Subcommittee.
Reader comments
1882 × 6 in gold, and thruppence more
-Pennsylvania-18_Jun_1764.jpg)
Featured articles
Two featured articles were promoted this week.

- Sind sparrow (nominated by Innotata) is a bird of the sparrow family Passeridae, found around the Indus valley region in South Asia. While the birds are "somewhat obscure", according to the nominator, the IUCN Red List classifies it as a species of "least concern".
- Alsos Mission (nominated by Hawkeye7) Part of the Manhattan Project, the effort during World War II by the Allies, principally Britain and the United States, to create an atomic bomb. The Manhattan Project was also charged with coordinating foreign intelligence related to enemy nuclear activity, and the Alsos Mission was an effort to find out what the German research programs had discovered, and prevent the research from getting to the Russians.
Featured lists
One featured list was promoted this week.
- The Smiths discography (nominated by SchroCat) The four studio albums, one EP, one live album, ten compilation albums, twenty singles, one video album and fourteen music videos on the Rough Trade, Sire and WEA record labels by The Smiths.
Featured pictures
Ten featured pictures were promoted this week.

- Twenty-dollar, fifty-dollar, one-hundred-dollar, five-hundred-dollar, five-thousand-dollar, and ten-thousand-dollar gold certificates from the 1882 series (created and nominated by Godot13) The 1882 series of U.S. Gold Certificates was nominated as a set. These bills, used to show ownership of gold instead of storing the actual gold, are the latest outcomes of Godot13's work with the Smithsonian Institution on the documentation of currency.
- John Hay (created by C.M. Gilbert, restored and nominated by Adam Cuerden) John Hay, private secretary to President Abraham Lincoln, and Secretary of State under William McKinley and Theodore Roosevelt. Readers may recognise this image: Adam Cuerden restored it in celebration of the article on John Hay reaching featured article status, as reported in the 13 August issue of the Signpost.
- John Jellicoe, 1st Earl Jellicoe (created by Bain News Service, restored and nominated by Adam Cuerden) British Admiral John Jellicoe (5 December 1859 – 20 November 1935). He is wearing the uniform of the Admiral of the Fleet, which rank he achieved in 1919. This image forms part of the Military History Wikiproject's attempt to celebrate the ongoing centenary of World War I.
- U.S. Colonial note printed by Benjamin Franklin (created by Benjamin Franklin and David Hall, nominated by Godot13) Three pence Colonial currency from the Province of Pennsylvania, as printed by Benjamin Franklin. The rough borders are typical for currency from this era; horrifyingly, many dealers will take scissors to these ancient currencies to neaten them up and make them fit modern æsthetics. Learning this resulted in quite a bit of cringing.
- New Court of Corpus Christi College (created by David Iliff, nominated by Armbrust) David Iliff, a.k.a. Diliff, continues his photography of Britain's cathedrals and universities with the New Court of Corpus Christi College, part of Cambridge University.

Reader comments
Automated copy-and-paste detection under trial
One of the problems Wikipedia faces is users who add content copied and pasted verbatim from sources. When we follow up on a person's work, we often don't check for this, and a few editors have managed to make thousands of edits over many years before concerns are detected. In the past year, I've picked up three or four editors who have made many thousands of edits to medical topics in which their additions contain word-for-word copy from elsewhere. Most of those who only make a few edits of this nature are usually never detected.
After a user detects this kind of editing, clean-up involves going through all their edits and occasionally reverting dozens of articles. Unfortunately, sometimes it means going back to how an article was years back, resulting in the loss of the efforts of the many editors who came after them. Contingency reverts can end up harming overall article quality and frustrate the core editing community. What is the point of contributing to Wikipedia if it's simply a collection of copyright-infringed text cobbled together, and even your own original contributions disappear in the cleanup? Worse, the fallout can cause editors to retire. If we could have caught them early and explained the issues to them, we'd not only save a huge amount of work later on, but might retain editors who are willing to put in a great deal of time.
So what is the solution? In my opinion, we need near real-time automated analysis and detection of copyright concerns. I'd been trying to find someone to develop such a tool for more than two years; then, at Wikimania in London, I managed to corner a pywikibot programmer, ValHallASW, and convinced him to do a little work. This was followed by meeting a wonderful Israeli instructor from the Sackler School of Medicine Shani Evenstein who knew two incredibly able programmers, User:Eran and User:Ravid ziv. By the end of Wikimania our impromptu team had produced a basic bot – User:EranBot – that does what I'd envisioned. It works by taking all edits over a certain size and running them through Turnitin / iThenticate. Edits that come back positive are listed for human follow-up. Development of this idea began back in March of 2012 by User:Ocaasi and can be seen here.
Why near real time?
Determining copy-and-paste issues becomes more difficult the longer one waits between the initial edit and the checking, as one then has to deal with mirroring of Wikipedia content across the Internet. As well, many reliable sources – including peer-reviewed journals and textbooks – have begun borrowing liberally from Wikipedia without attribution. So if we're looking at copyright issues six months or a year down the road, we need to look at publication dates and go back in the article history to determine who is copying from whom.
In short, it's far more difficult for both humans and machines.
Why Turnitin?
Turnitin is an Internet-based plagiarism-prevention service created by iParadigms, LLC, first launched in 1997; it is one of the strategies used by some universities and schools to minimise plagiarism in student writing. The company that developed and owns the product has agreed to give us free access to their tools and API. Even though it's a for-profit company, there won't be obtrusive links from Wikipedia to their site, and no advertising for them will ever appear on Wikipedia.
Why would they want to be involved with us? Letting us use their tools doesn't cost them anything and is no disadvantage to shareholders. Some companies are willing to help us just because they like what we do. We've had a number of publishers donate large numbers of accounts to Wikipedians for similar reasons. They have extra capacity just sitting there, so why not give it away? They also know we're volunteers and are not going to buy their capacity anyway. Other options could include Google, but they don't allow their services to be used in this way, and it appears that Yahoo is currently charging for use by User:CorenSearchBot, which checks new articles for issues.
Benefits
How many edits are we looking at? Currently the bot is running only on the English Wikipedia's medical articles. In 2013, there were 400,000 edits to medical content – around 1,100 edits per day. Of these only about 10% are of significant size and not a revert, so we're looking at an average of around maybe 100 edits per day. If we assume a 10% rate of copyright concerns and three times as many false positives as true positives, we're looking at 40 edits per day at most. Who would follow-up? With the number of concerning edits in the range of 40 per day, members of WikiProject Medicine will be able to handle the load. This is much easier than catching 30,000 edits of copyright infringement after the fact, with clean-up taking many of us away from writing content for many days.
The Wiki Education Foundation has expressed interest in the development of this tool, since edits by students have previously contained significant amounts of plagiarism, kindling much discontent with Wiki Education's predecessor. The Hebrew Wikipedia is also currently working with this bot, and we'd be happy to see other topic areas and WMF language sites use it.
There are still a few rough aspects to iron out. The parsing out of the new text added by an edit is not as good as it could be. Reverts should be ignored. These issues are fairly minor to address, and a number have already been dealt with. While there were initially about three false positives for every true positive, we should have this down to a more even 50–50 split by the end of the week. Already in its early stages, this has turned out to be an exceedingly useful tool.
- The views expressed in this opinion piece are those of the author only; responses and critical commentary are invited in the comments section. Editors wishing to propose their own Signpost contribution should email the Signpost's editor in chief.
Reader comments
Holding pattern
This week we saw three of the top ten articles remain in place, with the Ice Bucket Challenge at #1, Amyotrophic lateral sclerosis at #2, and Islamic State of Iraq and the Levant at #5, all for a second straight week. The death of English actor Richard Attenborough was apparently the most notable of the week, as that article entered the list at #3. Top news subjects of recent weeks, including Ebola virus disease (#7) and Robin Williams (#9), also continued to remain popular.
For the full top 25 list, see WP:TOP25. See this section for an explanation for any exclusions.
For the week of 24 to 30 August 2014, the 10 most popular articles on Wikipedia, as determined from the report of the 5,000 most viewed pages, were:
Rank Article Class Views Image Notes 1 Ice Bucket Challenge 
1,773,522 
Number 1 for the second week in a row. This global viral phenomenon to arise awareness and funding for research on ALS was not launched by any particular charity, but seems to have grown on its own. While it certainly has achieved its goals, some have criticized the whole movement as feeling more like an act of slacktivism by many participants. But most viral phenomena have absolutely no redeeming social value (has Grumpy Cat raised millions for disease research?), so things could be much worse. Wikipedia did its part to keep things focused on substance by deleting the celebrity-fest page "List of Ice Bucket Challenge participants" on 29 August, after a lengthy deletion debate. 2 Amyotrophic lateral sclerosis 
880,652 
Like #1, it's #2 for the second week in a row. 3 Richard Attenborough
794,061 
This popular English actor died on August 24, at age 90. Attenborough won two Academy Awards as director and producer for Gandhi in 1983. He also won four BAFTA Awards and four Golden Globe Awards during his career. As an actor, memorable appearances included roles in Brighton Rock (1947), The Great Escape (1963), 10 Rillington Place (1971), and Jurassic Park (1993). He is survived by his wife of almost 70 years, former actress Sheila Sim. 4 Ariana Grande 
589,596 
Up from #19 last week, the popular singer released her second album, My Everything, on August 25. 5 Islamic State of Iraq and the Levant
448,261 
Holding steady at #5 for a second week. This almost absurdly brutal jihadist group proudly posts mass executions it carries out on Twitter, and has been disowned even by al-Qaeda. The recent execution of journalist James Foley is among the reasons for the continued popularity of this article. 6 Deaths in 2014 
361,006 The list of deaths in the current year is always a popular article. Deaths this week included Leonid Stadnyk (August 24), a Ukrainian formerly listed by Guinness as the tallest man in the world; Swedish comic strip artist Lars Mortimer (August 25); Nigerian pastor Samuel Sadela (pictured at left), unverified claimant to being the oldest male alive (August 26); American particle physicist Victor J. Stenger (August 27); Former Soviet spy John Anthony Walker (August 28); Singaporean comedian David Bala (August 29); and 18-year old Belgian cyclist Igor Decraene, who died in a train accident (August 30). 7 Ebola virus disease
356,594 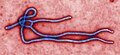
The 2014 West Africa Ebola outbreak continues to draw attention to this horrific disease. 8 Pseudoscorpion
334,956 
Reddit noted this week that "tiny pseudoscorpions (about 4mm) live inside old books, effectively protecting them by eating booklice and dustmites", a hook exciting enough to make reddit put this in the top 10 this week. 9 Robin Williams
332,653 
Down from #3 last week. The unexpected death by suicide of this iconic comic on August 11 led to one of the highest spikes in views since this project began. 10 Facebook
328,386 
Usually a fairly popular article; a slower news week allowed it to percolate back up into the Top 10 for the first time in a while.







.jpg)
.JPG)
Reader comments
Gray's Anatomy (v. 2)
This week, the Signpost went out to meet WikiProject Anatomy, dedicated to improving the articles about all our bones, brains, bladders and biceps, and getting them to the high standard expected of a comprehensive encyclopaedia. Begun back in 2005 by Phyzome, this project has its own Manual of Style, a huge to-do list, and yet only 30 active members helping to achieve anatomical greatness. So, we asked CFCF, Flyer22 and LT910001 for their opinions on this vital corner of the wiki documenting our own bodies.
What motivated you to join WikiProject Anatomy? Do you have a background in medicine or biology, or are you simply interested in the topic?
- CFCF: I found the image content on Wikipedia very useful when studying anatomy, and at the same time I realised there were PD sources out there that hadn't been used. I basically started uploading things from my local library which got me into writing, which got me hooked.
- Flyer22: I originally became interested in Wikipedia simply to document a certain soap opera couple. A lot of people come to Wikipedia to write about a certain thing, and then branch out into other areas they are knowledgeable and/or interested in. I am one of those people. I moved from soap operas, to general fiction, celebrity topics, etc., to sexual topics; and anatomy comes along with sexual topics, so then I got involved with anatomy topics. I have extensive knowledge of female anatomy, and it was easy to move right into that field on Wikipedia. While I am well versed in other topics, such as the science topic the Big Bang, and will pop up at strictly-scientific articles here and there, I decided not to focus on those topics on Wikipedia; there are some things that I am interested in that I'd rather not make into "work for Wikipedia." And it is all work, in my opinion, not so much fun. I also decided long ago that, like some other parts of my life, it's best not to name my profession(s) on Wikipedia; I am interested in a variety of Wikipedia topics and don't want to be pigeonholed as a certain type of editor, interest-wise; despite that, due to my expansive work on Wikipedia mostly focusing on sexual topics for years now, many Wikipedians think of me as a "sexual editor."
- LT910001: I would often use Wikipedia as a broad overview to learn about different parts of the body. It was very frustrating, because many articles were written very technically. Anatomy is the study of the human body, and we all have one, so the knowledge should be accessible to lay users. In addition, articles in general have not received much attention, and many are lacking sources or missing key information (such as information about diseases that affect the structure, common variations in the structure, and development). With some other users, I have set off to set this right.

Have you contributed to any of the project's four Featured or thirteen Good articles, and are these sort of articles generally easier or harder to promote than other subjects?
- CFCF: Yes, I wrote Cranial nerve. My personal experience is that when it comes to fact checking people are timid about reviewing anything related to medicine. I know it can be hard without prior knowledge of the subject, and there are only so many of us on Wikipedia that have that. One of the benefits in anatomy is that you can pretty much pick up any source from after 1950 and it's going to be decent, so fact-checking is simpler than in pure medical topics.
- Flyer22: Yes, I wrote the vast majority of the Clitoris article, and I'm still tweaking that article and/or adding things to it. I think that articles such as the Human brain or Heart are among the most difficult articles to promote to Good or Featured article status; this is because, unlike a lot of other anatomy topics, there are so many parts to these two organs and so much that has therefore been written about them. Editors have to be careful, especially in the case of the human brain, that they have all of the relevant aspects covered and are not including anything that has been superseded in science unless made clear that it has been superseded in science; there are things about the brain, such as the limbic system, that scientists thought they knew...but scientists of today have discovered or contend are inaccurate or somewhat inaccurate. Some sexual anatomy articles, whether it's one about the male anatomy (the Human penis article, for example, currently needs a lot of work) or one about female anatomy (the Cervix article is currently at WP:Good article status and editors are seeking to take it to Featured article status), are also challenging articles to promote; this is due to the complexity of (some of) these organs, newer research about them, and social aspects (including politics).
- LT910001: Yes, I wrote 7-8 and helped write Cranial nerves and Sebaceous gland. When I came to the project, there were 5 good articles. These were about neurological structures (eg Brain), or structures with social and cultural significance (Clitoris). Because there were no model articles which could demonstrate how what a purely anatomical structure would look like as a GA, I set out to create some as models, to show it could be done. We first had to get the structure right for articles, and that involved discussions at the manual of style for anatomy articles. I outlined this at the time in our first newsletter, which was sort of a manifesto about things we need to get the project going again. Since that newsletter, we've doubled the number of GA, B-class, and C-class articles, as a result of uploading new content, reassessment of articles, and swallowing up a batch of neuroanatomy articles. The articles I bought to GA were Cervix, Foramen spinosum, Parathyroid gland, Recurrent laryngeal nerve, Stapes, Suspensory ligament of the duodenum, and the featured list Anatomical terms of motion. With any luck, there'll be many more to come.
Can you explain your scope: what sort of articles qualify to be tagged under this project and what kind of things you don't cover?
- CFCF: Anything related to physiological (that is to say healthy) human anatomy. At first you think this is a limited number of articles, then you realise all anatomical variations are included. For example all the accessory bones, muscles or other organs that aren't inherently pathological.

The hand normally has 8 carpal bones, but may have a larger number of accessory ossicles or sesamoid bones. This image shows over 30 different bones. - LT910001: This is actually quite a troublesome question, and something we've put a lot of thought into recently. We cover articles relating to human anatomy. The rub here lies in whether we should have individual articles about every single substructure, or whether they should be represented as single articles. We did, at one time, have an article Root of spine of scapula. The problem here is that these articles are taken straight from Gray's Anatomy 1918 and are very unloved and untended. By rolling them into bigger articles (such as Spine of scapula or even Scapula), we can draw attention to articles, make editing easier, and perhaps re-expand when the articles are more fully fleshed out.

What is your most popular topic or article, measured by reader page views? Should it be a project aim to improve your highest visibility articles?
- CFCF: On our most popular list there are two main themes: the major organs are one, and sexual content is the other. In the project we aim to focus on improving content that is high visibility and high importance–which doesn't exclude sexual content per say.
We just rather focus on Heart, Liver, Cervix than Low importance topics. - Flyer22: Our most popular anatomy articles, as shown at Wikipedia:WikiProject Anatomy/Popular pages and as acknowledged by this Slate source, are some of the sexual anatomy articles. This is not surprising, at least to me, given the provocative nature and power of sexuality. A man is much more likely to be interested in the anatomy of the human penis than, for example, the anatomy of his hand or sternum. Given how much misinformation is out there about sexuality, especially female sexuality and female sexual anatomy, it is very important to me that these articles be improved to where they should be on the quality scale; if not a WP:Good or WP:Featured article, these articles should at least be of B-quality. I responded on Wikipedia to the Slate article, as seen in with this link, and have steadily been improving the Vagina article.
- LT910001: I agree with CFCF. We have been working on the corpus of organ-related articles, which includes the articles Breast and Cervix. Sex-related articles in generally get a lot of attention, and I think it is the article about pure anatomy which need work.
What are the primary resources used for writing an anatomy article? Do you solely rely on medical experts or are more mainstream references also fine?
- CFCF: Without insulting all to many people I'll make use of the pun: "Anatomy is a dead science". Apart from smaller advancements–macroscopic anatomy hasn't really moved in the last 100–120 years. New naming conventions have come with the TA, but for the most part–what stood true in 1890 about large scale anatomy is true today. This means certain aspects of WP:MEDRS are very hard to follow: for example we don't bother looking for "reviews from the past 5 years" – because in the case there are any reviews at all they are often from 1970–80 at best. Any college level or more advanced text-book from the past 70 years should be a viable source for us.
Anatomy is also very visual, which means we need to use images, and old images are fine: I recently had a featured image from 1909. As for resources that can be found online, I'm in the middle of compiling a list of free resources, and of course there are the ~4000 images I have (only half of which I've uploaded) which haven't found their appropriate article.
Muscles of the face, recently a featured image and still relevant 105 years after it was created. - Flyer22: I'm not sure that I would call anatomy a dead science, but, like CFCF has indicated, it has not advanced as much as many other medical fields. This is primarily because so much of what scientists know about anatomy is the same as it was many years ago. For other topics, such as the human brain or aspects of female sexual anatomy, it's not always going to be the case that anatomy sources from 70 years ago are good to use. For example, for many years, scientists believed that the Bartholin's glands, which are located to the left and right of the vaginal opening, were the primary source of vaginal lubrication. These days, plasma seepage from the vaginal walls (vaginal transudation) are what the vast majority (if not all) of scientists believe to be the primary source of vaginal lubrication. Other aspects of female sexual anatomy, such as the clitoris, have also been misrepresented in anatomical texts (intentionally or unintentionally). We adhere to WP:MEDRS as much as we can. For example, I recently had a discussion on my talk page about the Erogenous zone article and the need to adhere to WP:MEDRS and therefore try to stay away from WP:Primary sources even though the topic of erogenous zones outside of studying the genitals is not well-researched. Primary sources or media sources, unless reporting on social aspects or used as an adjunct to a scholarly source (for example, Template:Citation Style documentation/lay), should generally not be used for anatomy topics. If it's an aspect that's not well studied and has no review articles yet, the primary source might be suitable for use. WP:MEDRS (in this section, for instance) is clear about its exceptions.
- LT910001: There is a view that anatomy is a 'dead' science, however the advent of small cameras and high-quality imaging has completely revolutionised the field. Many doctors and surgeons are super-specialising, and there are an increasing number of very particular resources, such as books entirely about small anatomical structures. Locating these resources is very useful, and often the most useful resources come out in the last 10–15 years. These resources aggregate historical opinions of anatomists with recent epidemiological studies, such as of anatomical variation. Something that is very difficult in editing anatomical articles is understanding that a lot of anatomy teaching derives from a very small group of original authors such as Henry Gray that are quoted and requoted in literature and other textbooks until the opinions and experiences of those authors have become fact. For users interested in contributing, books, textbooks and atlases are very useful, because they are so information dense.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
How close are your links with WikiProject Medicine, a related project? Do many members participate in both WikiProjects?
- CFCF: I'd have a hard time coming up with anyone involved in this project who isn't also a member of that project–which is unfortunate as we would hope to attract more general Wikipedians as well. On the other hand we have the benefit of being able to ask for help whenever we have a larger project, as recently on Heart.
- Flyer22: Yes, WikiProject Anatomy's ties to WP:Med are significant since anatomy is a medical aspect. Some of our editors are involved with both WikiProjects, but I think we also have some on our Participants list who are not.
- LT910001: There are indeed a number of users who cover both projects, however there are also a number of members who edit purely anatomy-related articles.
What is the reason you exclusively cover human anatomy and not the body parts of other animals? No project seems to be looking after articles such as Thorax.
- CFCF: We've more or less formed as a group of editors with human anatomical expertise, so knowledge of animal or comparative anatomy is limited. We do strive to have a section on other animals in every article, and for FA or GA it is pretty much required to be sufficient in scope. Previously this has been the field of WikiProject Veterinary Medicine & WikiProject Organismal biomechanics.
That we hadn't tagged Thorax is more of an oversight than anything else. With over 9000 articles we occasionally miss even high-importance ones such as thorax, or until recently Limbic system. - LT910001: There are a few reasons. It is easier to draw a bright line that delineates what relates to human anatomy and what doesn't. "Animal" anatomy could be very broad and we have the good fortune of not (unlike the related project WikiProject Medicine) being constantly embroiled in discussions about what relates to our scope. Other reasons for focusing on human anatomy include our strong crossover membership with WikiProject Medicine, the existence of a number of other animal-related projects such as WikiProject Animals and WikiProject Mammals, and the interests of our members.
How can a new member help today?
- LT910001: Drop in to our Wikiproject, pick some articles, and improve them! We're always looking for people to collaborate with in the project and am happy to collaborate with whatever interests users who drop by. Something we are in great need of is sourcing articles, and users who can write in plain English. There is so much to improve and always room for more hands. Something very helpful a new member could do is go to their local library, find an anatomy book, and start using it to source.
- CFCF: This completely depends on prior knowledge. Someone who is completely new to anatomy could appropriate text from the CC-BY Openstax Anatomy & Physiology book–something which requires little previous knowledge and could be very educational. If you're into working on images there is so much out there that I could point to, and if you want to write all you need to do is pick up an anatomical textbook and write.
Anything else you'd like to add?
- LT910001: Superficially, anatomy is dry and dull and a dead science. However if you go a little deeper, it's a lively and very active field, with new publications coming out all the time. Anatomy is a fascinating look into how our bodies are structured and develop and I hope more users decide to contribute.
Better get your syntax all fixed in time for next week, when we'll be venturing out of content to spend some time with a project that never misses an error. Until then, why not look for some mistakes in the archive?
Reader comments
A Wikipedia-based Pantheon; new Wikipedia analysis tool suite; how AfC hamstrings newbies
A monthly overview of recent academic research about Wikipedia and other Wikimedia projects, also published as the Wikimedia Research Newsletter.
Wikipedia in all languages used to rank global historical figures of all time

A research group at MIT led by Cesar A. Hidalgo published[1] a global "Pantheon" (probably the same project already mentioned in our December 2012 issue), where Wikipedia biographies are used to identify and "score" thousands of global historical figures of all time, together with a previous compilation of persons having written sources about them. The work was also covered in several news outlets. We won't summarise here all the details, strengths and limits of their method, which can already be found in the well-written document above.
Many if not most of the headaches encountered by the research group lie in the work needed to aggregate said scores by geographical areas. It's easy to get the city of birth of a person from Wikipedia, but it's hard to tell to what ancient or modern country that city corresponds, for any definition of "country". (Compare our recent review of a related project by a different group of researchers that encountered the same difficulties: "Interactions of cultures and top people of Wikipedia from ranking of 24 language editions".) The MIT research group has to manually curate a local database; in an ideal world, they'd just fetch from Wikidata via an API. Aggregation by geographical area, for this and other reasons, seems of lesser interest than the place-agnostic person rank.
The most interesting point is that a person is considered historically relevant when being the subject of an article on 25 or more editions of Wikipedia. This method of assessing an article's importance is often used by editors, but only as an unscientific approximation. It's a useful finding that it proved valuable for research as well, though with acknowledged issues. The study is also one of the rare times researchers bother to investigate Wikipedia in all languages at the same time and we hope there will be follow-ups. For instance, it could be interesting to know which people with an otherwise high "score" were not included due to the 25+ languages filter, which could then be further tweaked based on the findings. As an example of possible distortions, Wikipedia has a dozen subdomains for local languages of Italy, but having an article in 10 italic languages is not an achievement of "global" coverage more than having 1.
The group then proceeded to calculate a "historical cultural production index" for those persons, based on pageviews of the respective biographies (PV). This reviewer would rather call it a "historical figures modern popularity index". While the recentism bias of the Internet (which Wikipedia acknowledges and tries to fight back) for selection is acknowledged, most of the recentism in this work is in ranking, because of the usage of pageviews. As WikiStats shows, 20% of requests come from a country (the US) with only 5% of the world population, or some 0.3% of the total population in history (assumed as ~108 billion). Therefore there is an error/bias of probably two orders of magnitude in the "score" for "USA" figures; perhaps three, if we add that five years of pageviews are used as sample for the whole current generation. L* is an interesting attempt to correct the "languages count" for a person (L) in the cases where visits are amassed in single languages/countries; but a similar correction would be needed for PV as well.
From the perspective of Wikipedia editors, it's a pity that Wikipedia is the main source for such a rank, because this means that Wikipedians can't use it to fill gaps: the distribution of topic coverage across languages is complex and far from perfect; while content translation tools will hopefully help make it more even, prioritisation is needed. It would be wonderful to have a rank of notably missing biographies per language editions of Wikipedia, especially for under-represented groups, which could then be forwarded to the local editors and featured prominently to attract contributions. This is a problem often worked on, from ancient times to recent tools, but we really lack something based on third party sources. We have good tools to identify languages where a given article is missing, but we first need a list (of lists) of persons with any identifier, be it authority record or Wikidata entry or English name or anything else that we can then map ourselves.
The customary complaint about inconsistent inclusion criteria can also be found: «being a player in a second division team in Chile is more likely to pass the notoriety criteria required by Wikipedia Editors than being a faculty at MIT», observe the MIT researchers. However, the fact that nobody has bothered to write an article on a subject doesn't mean that the project as a whole is not interested in having that article; articles about sports people are just easier to write, the project needs and wants more volunteers for everything. Hidalgo replied that he had some examples of deletions in mind; we have not reviewed them, but it's also possible that the articles were deleted for their state rather than for the subject itself, a difference to which "victims" of deletion often fail to pay attention to.
WikiBrain: Democratizing computation on Wikipedia
– by Maximilianklein
When analyzing any Wikipedia version, getting the underlying data can be a hard engineering task, beyond the difficulty of the research itself. Being developed by researchers from Macalester College and the University of Minnesota, WikiBrain aims to "run a single program that downloads, parses, and saves Wikipedia data on commodity hardware." [2] Wikipedia dump-downloaders and parsers have long existed, but WikiBrain is more ambitious in that it tries to be even friendlier by introducing three main primitives: a multilingual concept network, semantic relatedness algorithms, and geospatial data integration. With those elements, the authors are hoping that Wikipedia research will become a mix-and-match affair.

The first primitive is the multilingual concept network. Since the release of Wikidata, the Universal Concepts that all language versions of Wikipedia represent have mostly come to be defined by the Wikidata item that each language mostly links to. "Mostly" is a key word here, because there are still some edge cases, like the English Wikipedia's distinguishing between the concepts of "high school" and "secondary school", while others do not. WikiBrain will give you the Wikidata graph of multilingual concepts by default, and the power to tweak this as you wish.
The next primitive is semantic relatedness (SR), which is the process of quantifying how close two articles are by their meaning. There have been literally hundreds of SR algorithms proposed over the last two decades. Some rely on Wikipedia's links and categories directly. Others require a text corpus, for which Wikipedia can be used. Most modern SR algorithms can be built one way or another with Wikipedia. WikiBrain supplies the ability to use five state-of-the-art SR algorithms, or their ensemble method – a combination of all 5.
Already at this point an example was given of how to mix our primitives. In just a few lines of code, one could easily find which articles in all languages were closest to the English article on "jazz", and which were also a tagged as a film in Wikidata.
The last primitive is a suite of tools that are useful for spatial computation. So extracting location data out of Wikipedia and Wikidata can become a standardized process. Incorporated are some classic solutions to the "geoweb scale problem" – that regardless of an entity's footprint in space, it is represented by a point. That is a problem one shouldn't have to think about, and indeed, WikiBrain will solve it for you under the covers.
To demonstrate the power of WikiBrain the authors then provide a case study wherein they replicate previous research that took "thousands of lines of code", and do it in "just a few" using WikiBrain's high-level syntax. The case study is cherry-picked as is it previous research of one of the listed authors on the paper – of course it's easy to reconstruct one's own previous research in a framework you custom-built. The case study is a empirical testing of Tobler's first law of geography using Wikipedia articles. Essentially one compares the SR of articles versus their geographic closeness – and it's verified they are positively linked.
Does the world need an easier, simpler, more off-the-shelf Wikipedia research tool? Yes, of course. Is WikiBrain it? Maybe or maybe not, depending on who you are. The software described in the paper is still version 0.3. There are notes explaining the upcoming features of edit history parsing, article quality ranking, and user data parsing. The project and its examples are written in Java, which is a language choice that targets a specific demographic of researchers, and alienates others. That makes WikiBrain a good tool for Java programmers who do not know how to parse off-line dumps, and have an interest in either multilingual concept alignment, semantic relatedness, and spatial relatedness. For everyone else, they will have to make do with one of the other 20+ alternative parsers and write their own glueing code. That's OK though; frankly the idea to make one research tool to "rule them all" is too audacious and commandeering for the open-source ecosystem. Still that doesn't mean that WikiBrain can't find its userbase and supporters.
Newcomer productivity and pre-publication review
It's time for another interesting paper on newcomer retention[3] from authors with a proven track record of tackling this issue. This time they focus on the Articles for Creation mechanism. The authors conclude that instead of improving the success of newcomers, AfC in fact further decreases their productivity. The authors note that once AfC was fully rolled out around mid-2011, it began to be widely used – the percentage of newcomers using it went up from <5% to ~25%. At the same time, the percentage of newbie articles surviving on Wikipedia went down from ~25% to ~15%. The authors hypothesize that the AfC process is unfriendly to newcomers due to the following issues: 1) it's too slow, and 2) it hides drafts from potential collaborators.
The authors find that the AfC review process is not subject to insurmountable delays; they conclude that "most drafts will be submitted for review quickly and that reviews will happen in a timely manner.". In fact, two-thirds of reviews take place within a day of submission (a figure that positively surprised this reviewer, though a current AfC status report suggests a situation has worsened since: "Severe backlog: 2599 pending submissions"). In either case, the authors find that about a third or so of newcomers using the AfC system fail to understand the fact that they need to finalize the process by submitting their drafts to the review at all – a likely indication that the AfC instructions need revising, and that the AfC regulars may want to implement a system of identifying stalled drafts, which in some cases may be ready for mainspace despite having never been officially "submitted" (due to their newbie creator not knowing about this step or carrying it out properly).
However, the authors do stand by their second hypothesis: they conclude that the AfC articles suffer from not receiving collaborative help that they would get if they were mainspaced. They discuss a specific AfC, for the article Dwight K. Shellman, Jr/Dwight Shellman. This article has been tagged as potentially rescuable, and has been languishing in that state for years, hidden in the AfC namespace, together with many other similarly backlogged articles, all stuck in low-visibility limbo and prevented from receiving proper Wikipedia-style collaboration-driven improvements (or deletion discussions) as an article in the mainspace would receive.
The researchers identify a number of other factors that reduce the functionality of the AfC process. As in many other aspects of Wikipedia, negative feedback dominates. Reviewers are rarely thanked for anything, but are more likely to be criticized for passing an article deemed problematic by another editor; thus leading to the mentality that "rejecting articles is safest" (as newbies are less likely to complain about their article's rejection than experienced editors about passing one). AfC also suffers from the same "one reviewer" problem as GA – the reviewer may not always be qualified to carry out the review, yet the newbies have little knowledge how to ask for a second opinion. The authors specifically discuss a case of reviewers not familiar with the specific notability criteria: "[despite being notable] an article about an Emmy-award winning TV show from the 1980's was twice declined at AfC, before finally being published 15 months after the draft was started". Presumably if this article was not submitted to a review it would never be deleted from the mainspace.
The authors are critical of the interface of the AfC process, concluding that it is too unfriendly to newbies, instruction wise: "Newcomers do not understand the review process, including how to submit articles for review and the expected timeframe for reviews" and "Newcomers cannot always find the articles they created. They may recreate drafts, so that the same content is created and reviewed multiple times. This is worsened by having multiple article creation spaces(Main, userspace, Wikipedia talk, and the recently-created Draft namespace".
The researchers conclude that AfC works well as a filtering process for the encyclopedia, however "for helping and training newcomers [it] seems inadequate". AfC succeeds in protecting content under the (recently established) speedy deletion criterion G13, in theory allowing newbies to keep fixing it – but many do not take this opportunity. Nor can the community deal with this, and thus the authors call for a creation of "a mechanism for editors to find interesting drafts". That said, this reviewer wants to point out that the G13 backlog, while quite interesting (thousands of articles almost ready for main space ...), is not the only backlog Wikipedia has to deal with – something the writers overlook. The G13 backlog is likely partially a result of imperfect AfC design that could be improved, but all such backlogs are also an artifact of the lack of active editors affecting Wikipedia projects on many levels.
In either case, AfC regulars should carefully examine the authors suggestions. This reviewer finds the following ideas in particular worth pursuing. 1) Determine which drafts need collaboration and make them more visible to potential editors. Here the authors suggest use of a recent academic model that should help automatically identify valuable articles, and then feeding those articles to SuggestBot. 2) Support newcomers' first contributions – almost a dead horse at this point, but we know we are not doing enough to be friendly to newcomers. In particular, the authors note that we need to create better mechanisms for newcomers to get help on their draft, and to improve the article creation advice – especially the Article Wizard. (As a teacher who has introduced hundreds of newcomers to Wikipedia, this reviewer can attest that the current outreach to newbies on those levels is grossly inadequate.)
A final comment to the community in general: was AfC intended to help newcomers, or was it intended from the start to reduce the strain on new page patrollers by sandboxing the drafts in the first place? One of the roles of AfC is to prevent problematic articles from appearing in the mainspace, and it does seem that in this role it is succeeding quite well. English Wikipedia community has rejected the flagged revisions-like tool, but allowed implementation of it on a voluntary basis for newcomers, who in turn may not often realize that by choosing the AfC process, friendly on the surface, they are in fact slow-tracking themselves, and inviting extraordinary scrutiny. This leads to a larger question that is worth considering: we, the Wikipedia community of active editors, have declined to have our edits classified as second-tier and hidden from the public until they are reviewed, but we are fine pushing this on to the newbies. To what degree is this contributing to the general trend of Wikipedia being less and less friendly to newcomers? Is the resulting quality control worth turning away potential newbies? Would we be here if years ago our first experience with Wikipedia was through AfC?
Briefly

- 15% of PLOS Biology articles are cited on Wikipedia: A conference paper titled "An analysis of Wikipedia references across PLOS publications"[4] asked the following research questions: "1) To what extent are scholarly articles referenced in Wikipedia, and what content is particularly likely to be mentioned?" and "2) How do these Wikipedia references correlate with other article-level metrics such as downloads, social media mentions, and citations?". To answer this, the authors analyzed which PLOS articles are referenced on Wikipedia. They found that as of March 2014, about 4% of PLOS articles were mentioned on Wikipedia, which they conclude is "similar to mentions in science blogs or the post-publication peer review service, F1000Prime". About half of articles mentioned on Wikipedia are also mentioned on Facebook, suggesting that being cited on Wikipedia is related to being picked up by other social media. Most of Wikipedia cites come from PLOS Genetics, PLOS Biology and other biology/medicine related PLOS outlets, with PLOS One accounting for only 3% total, though there are indications this is changing over time. 15% of all articles from PLOS Biology have been cited on Wikipedia, the highest ratio among the studied journals. Unfortunately, this is very much a descriptive paper, and the authors stop short of trying to explain or predict anything. The authors also observe that "By far the most referenced PLOS article is a study on the evolution of deep-sea gastropods (Welch, 2010) with 1249 references, including 541 in the Vietnamese Wikipedia."
- "Big data and small: collaborations between ethnographers and data scientists":[5] Ethnography is often seen as the least quantitative branch of social science, and this essay-like article's style is a good illustration. This is, essentially, a self-reflective story of a Wikipedia research project. The author, an ethnographer, recounts her collaboration with two big data scholars in a project dealing with a large Wikipedia dataset. The results of their collaboration are presented here and have been briefly covered by our Newsletter in Issue 8/13. This article can be seen as an interesting companion to the prior, Wikipedia-focused piece, explaining how it was created, though it fails to answer questions of interest to the community, such as "why did the authors choose Wikipedia as their research ground" or about their experiences (if any) editing Wikipedia.
- "Emotions under discussion: gender, status and communication in online collaboration":[6] Researchers investigated "how emotion and dialogue differ depending on the status, gender, and the communication network of the ~12,000 editors who have written at least 100 comments on the English Wikipedia's article talk pages." Researchers found that male administrators tend to use an impersonal and neutral tone. Non-administrator females used more relational forms of communication. Researchers also found that "editors tend to interact with other editors having similar emotional styles (e.g., editors expressing more anger connect more with one another)." Authors of this paper will present their research at the September Wikimedia Research and Data showcase.
References
- ^ "Pantheon".
- ^ Sen, Shilad; Jia-Jun Li, Toby; WikiBrain Team; Hecht, Brent (2014). "WikiBrain: Democratizing computation on Wikipedia". Proceedings of the International Symposium on Open Collaboration (PDF). pp. 1–19. doi:10.1145/2641580.2641615. ISBN 978-1-4503-3016-9. S2CID 248410867.

- ^ Jodi Schneider, Bluma S. Gelley Aaron Halfaker: Accept, decline, postpone: How newcomer productivity is reduced in English Wikipedia by pre-publication review http://jodischneider.com/pubs/opensym2014.pdf OpenSym '14 , August 27–29, 2014, Berlin
- ^ Fenner, Martin; Jennifer Lin (June 6, 2014), "An analysis of Wikipedia references across PLOS publications", altmetrics14 workshop at WebSci, Figshare, doi:10.6084/m9.figshare.1048991
- ^ Ford, Heather (1 July 2014). "Big data and small: collaborations between ethnographers and data scientists". Big Data & Society. 1 (2) 2053951714544337. doi:10.1177/2053951714544337. ISSN 2053-9517.
- ^ Laniado, David; Carlos Castillo; Mayo Fuster Morell; Andreas Kaltenbrunner (August 20, 2014), "Emotions under Discussion: Gender, Status and Communication in Online Collaboration", PLOS ONE, 9 (8) e104880, Bibcode:2014PLoSO...9j4880I, doi:10.1371/journal.pone.0104880, PMC 4139304, PMID 25140870
Reader comments